
एकदा माझ्या मोठ्या मुलाला शाळेत मांसाहारी फुलाबद्दल (व्हिनस फ्लायट्रॅप) माहिती दिली होती पण त्याचे जे फोटो दाखवले ते ब्लॅक अॅन्ड व्हाइट होते. रंगीत फोटोसाठी तो माझ्यामागे लागला होता. त्याला फक्त फोटो बघायचे होते. मग त्याला मी म्हटले गुगल वर शोधुयात ना! गुगलच्या चित्रविभागाला साकडे घालून त्या फुलाची आणि त्यासारख्या दुसर्या फुलांचीही चित्रे त्याला दाखवून गुगलच्या शोध जगताची अलीबाबाची गुहा त्याला उघडून देली. काहीही शोधायचे असल्यास गुगल मध्ये सर्च करून माहिती मिळवता येते, ह्या कल्पनेने तो एकदम खुष झाला. मग त्याचे आणि माझे 'गुगल शोध' बद्दल झालेले बोलणे त्याने माझ्या धाकट्या मुलालाही सांगितले, प्रात्यक्षिकासहित. त्याचे त्यालाही कौतुक वाटून त्याचीही उत्सुकता चाळवली गेली.
'बाबा, गुगलवर आपण काहीपण शोधू शकतो?', गाल फुगवून आणि डोळे मोठ्ठे करून धाकट्याने विचारले. मी एकदम टेक सॅव्ही बाप असल्याच्या कौतुकाने त्याला म्हणालो, 'हो काहीपण, तुला काय शोधायचे ते सांग आपण शोधूया'. एकदम निरागसतेने त्याने विचारले, 'आई चिडल्यावर कधी-कधी तुम्ही म्हणता ना मला की नविन आई आणूयात! ही नविन आई पण आपण गुगलवर शोधू शकतो का?". च्यायला, ही आत्ताची लहान पिढी आपलेच दात आपल्या घशात कसे घालील ह्याचा काही नेम नाही. पण वेळ बरी होती, अर्धांग स्वयंपाकघरात गुंतलेले होते. मी लगेच, 'अरे चला तुम्हाला आइसक्रीम खायचे होते ना, जाऊया', असे म्हणून वेळ मारून नेण्यासाठी त्यांना घेऊन बाहेर पडलो. आईसक्रीमच्या खुषीत धाकटा त्याचा प्रश्न विसरून गेला. पण मोठ्या मुलाने, गुगलकडे ही सगळी माहिती अशी असते, तो ही सगळी माहिती आपल्याला अशी काय दाखवू शकतो असे 'समंजस' प्रश्न विचारले. त्याला समजावून देता देता लक्षात आले की 'एंटरप्राईज सर्च' ह्या क्षेत्रात काम केल्यामुळे माहिती झालेल्या ह्यातल्या तांत्रिक बाबींची माहिती साध्या आणि सोप्या भाषेत सर्वांनाच करू देता येईल. चला तर मग बघुयात हे सर्च इंजीन कसे काम करते ते...
आजच्या ऑनलाईन जगात इंटरनेट हे माहितीचे भांडार झाले आहे. सर्व लहान मोठ्या कंपन्या त्यांचे ब्रॅन्ड्स, त्यांची उत्पादने आणि सेवा ह्यांच्या माहितीसाठी आणि मार्केटींगसाठी इंटरनेटचा प्रभावी वापर करुन त्या भांडारात भर टाकत आहेत. वेब २.० ( Web 2.0 ) मुळे इंटरनेट वाचनीय न रहाता लेखनीयही झाले आहे. लाखो ब्लॉगर्स विवीध विषयांवर लेखन करून त्या भांडाराला दिवसेंदिवस समृद्ध करीत आहेत. ही सर्व माहिती, अफाट पसरलेल्या आणि गहन खोली असलेल्या महासागराप्रमाणे आहे. आता ह्या माहितीच्या अफाट सागरातून आपल्याला हवी असलेली नेमकी माहिती शोधायची म्हणजे अक्षरशः 'दर्या मे खसखस' शोधण्यासारखेच आहे. इथेच हे इंटरनेट सर्च इंजीन अल्लादिनच्या जादूच्या दिव्यातील जिनप्रमाणे आपल्या मदतीसाठी पुढे येते.
ही मदत करण्यासाठी इंटरनेट सर्च इंजीन अविरत कार्यरत असते. ह्या कामाची विभागणी खालील तीन मुलभूत प्रकारांत केलेली असते.
१
माग काढणे
(Web Crawling)
इंटरनेटवरील सर्व वेब पेजेसचा माग काढून, त्यांना भेट देऊन त्यावरील माहिती गोळा करणे
२
पृथ:करण आणि सूची करणे
(Analysis & Indexing)
गोळा केलेल्या माहितीचे पृथ:करण (Analysis) आणि सुसुत्रीकरण (Alignment) करून त्या माहितीचा जलद शोध घेण्यासाठी सूची (Index) बनवणे
३
शोध निकाल
(Search Result)
शोध घेणार्या इंटरनेट वापरकर्त्यांना (Users) सूची वापरुन योग्य तो शोध निकाल (Search Result) कमीत कमी वेळात दाखवणे
१. Web Crawling (माग काढणे)
आपल्याला हवी असलेली माहिती इंटरनेटवर नेमक्या कोणत्या पानावर आहे हे आपल्याला सांगण्याआधी ते पान इंटरनेट सर्च इंजीनला माहिती असले पाहिजे, हो ना? त्यासाठी सर्च इंजीनला अस्तित्वात असलेल्या सर्व वेब पेजेसचा मागोवा घ्यावा लागतो. रोज भर पडण्यार्या ह्या करोडो वेब पेजेसना भेट देऊन त्यांचा मागोवा घेणे हे काही खायचे काम नाही (ह्या खडतर कामाचा आवाका, मुलींचा मागोवा घेत फिरणार्यांना नक्की ध्यानात येईल ;) ). ह्यासाठी सर्च इंजीन्स, सोफ्ट्वेअर रोबोट्स वापरतात ज्यांना 'स्पायडर (Spider)' म्हटले जाते. हे स्पायडर्स अक्षरशः इंटरनेटभर सरपटत जाउन ही माहिती गोळा करतात म्हणून ह्या प्रक्रियेला Web Crawling म्हणतात. ही प्रक्रिया पुनरावर्तन (Recursion) प्रक्रिया असते म्हणजे सुरुवातीच्या, पहिल्या पानावर असलेल्या सर्व लिंक्स गोळा केल्या जातात आणि मग त्या प्रत्येक लि़कला भेट देऊन पुन्हा त्या पानावरच्या सर्व लि़क गोळा करून त्या प्रत्येक लिंकला भेट देत ह्याची आवर्तने होत राहतात.
आता कळीचा मुद्दा हा आहे की ह्या प्रत्येक पानाला भेट दिल्यावर काय माहिती गोळा केली जाते? प्रामुख्याने सर्व स्पायडर्स 'मजकूर स्वरूपातली (Text)' माहिती गोळा करतात. प्रत्येक सर्च इंजीन्सची आपापली विशीष्ट अशी अल्गोरिदम्स असतात ही माहिती गोळा करण्यासाठी. पण प्रामुख्याने वेब पेजचे टायटल, मेटा टॅग्स, हेडर टॅग्स, चित्रांना दिलेला मजकूर (Alt tag) ह्यांत असलेल्या Text ला जास्त वेटेज दिले जाते. कारण हा मजकूर त्या वेब पेजला 'डिफाईन' करत असतो. त्यानंतर Body tag मधला मजकूर गोळा केला जातो.
काही वेब साइट्सना काही पेजेसचा मागोवा घेऊ द्यायचा नसतो. अशा वेळी ह्या साइट्स Robots.txt नावाची फाईल त्यांच्या साइट्वर ठेवतात. ही फाइल म्हणजे स्पायडर्स आणि वेब साइट ह्यांच्यामधला करार (Robots Exclusion Protocol) असतो. ज्या वेब पेजेसना ह्या स्पायडर्सनी भेट देऊ नये असे ठरवले असते त्या वेब पेजेसची नावे (लिंक्स) ह्या फाइलमध्ये लिहीलेली असतात. स्पायडर्स Crawling किंवा पुनरावर्तन चालू करायच्या आधि ही फाइल वाचून त्याप्रमाणे लिंक्स मागोवा घेताना गाळतात.
२. Analysis & Indexing (पृथ:करण आणी सूचीकरण)
ही सगळी 'मजकुर (Text)' माहिती गोळा करून सर्च इंजिन्स त्यांच्या जवळ ठेवत नाहीत. त्या माहितीचे पृथ:करण करून त्यातली शोध घेण्याच्या कामी येणारी माहितीच फक्त वापरली जाते. पण हे पृथ:करण असते तरी काय?
पृथ:करण
ह्यात प्रथम जी माहिती गोळा केली आहे ती कोणत्या भाषेतली आहे ते तपसले जाते. त्या भाषेच्या अनुषंगाने पृथ:करण कार्यवाहक (Analysers) वापरले जातात. एकदा भाषा कळली की मग त्या Text चे प्रसामान्यीकरण (Normalization) केले जाते. ह्यासाठी वापरली जाणारी प्रोसेस 'Stemming किंवा Lemmatization' म्हणून ओळखली जाते. ह्यात शब्दांची विवीध रूपे (धातूसाधित रूपे) त्यांच्या मूळ (धातू) प्रकारात आणली जातात. ह्म्म.. जरा बोजड झाले ना, वोक्के, उदाहरण बघू म्हणजे समजेल.
car, cars, car's, cars' ह्याचे मूळ रूप car हे घेतले जाते. त्यामुळे जेव्हा 'car' हा शब्द सर्च टर्म म्हणून वापरला जाईल तेव्हा car चे कोणतेही रुप असलेली वेब पेजेस शोधली जातील.
अजून एक उदाहरण बघुयात,
"the boy's cars are different colors" वे वाक्य "the boy car differ color" असे Normalize केले जाईल. हे फक्त वानगीदाखल आहे. प्रत्यक्षात बरीच वेगवेगळी अल्गोरिदम्स वापरली जातात आणि ही प्रोसेस खुपच क्लिष्ट आहे.
सूचीकरण
आता ह्या नॉर्मलाईझ केलेल्या शब्दांच्या मूळ रुपांना (धातूंना) सूचीबद्ध केले जाते. ही सूची (फक्त समजण्यासाठी) पुस्तकाच्या शेवटी जी सूची (Index) असते, म्हणजे शब्दांची यादी आणि तो शब्द पुस्तकात कोण-कोणत्या पानांवर आलेला आहे ते पृष्ठ क्रमांक, साधारण तशीच, त्या प्रकारची एक सूची असते.

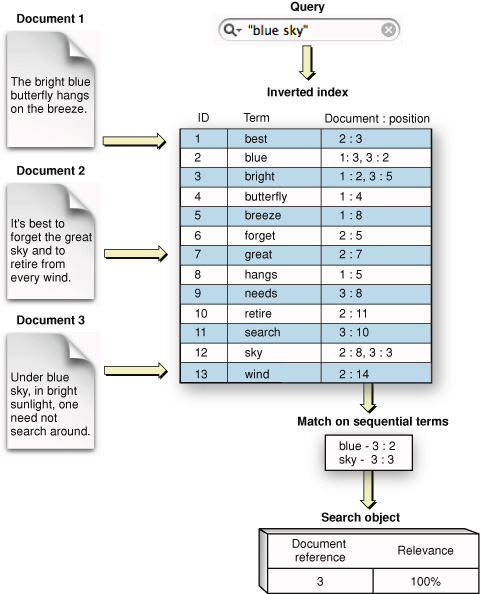
सर्च इंजीनच्या सूचीत नॉर्मलाईझ केलेले शब्दांचे मूळ रूप आणि ते कोण कोणत्या वेब पेजेस वर आले आहे त्यांची यादी असते. हेही फक्त वानगीदाखल आहे. हे सूचीकरण हा तर सर्च इंजीनचा आत्मा असतो आणि ते त्यांचे व्यावसायिक सिक्रेट असते. ह्या सूचीवरच सर्व डोलारा उभा असतो. ह्या सूचीला तांत्रिक भाषेत 'Inverted index' म्हणतात.

ह्या सूचीत तो शब्द त्या वेब पेज वर किती वेळा आला आहे, कुठे आला आहे, कुठल्या महत्वाच्या टॅग्स मध्ये आला आहे अशी विवीध माहिती असते. ह्या सूचीची रचना, सर्च इंजीन शोध निकाल किती जलद देऊ शकत ह्यासाठी फारच महत्वाची असते.
३. Search Result (शोध निकाल)
जेव्हा शोधकर्ता काही शोधण्यासाठी इंटरनेट सर्च इंजीन वापरतो तेव्हा जे शोधायचेय त्याच्यापेक्षा भलतीच काही वेब पेजेस शोध निकालात दिसली तर शोधकर्ता पुन्हा ते सर्च इंजीन वापरणारच नाही आणि तो असंतुष्ट वापरकर्ता (unsatisfied user) म्हणून गणला जाईल आणि असे unsatisfied user असणे सर्च इंजीनला परवडणार नाही (धंदा बसेल हो दुसरे काय, छ्या! मराठी माणसाला धंदा आणि तो बसला असे काही सांगितल्याशिवाय चटकन कळतच नाही). त्यासाठी शोध निकालातली अन्वर्थकता किंवा समर्पकता (relevance) फार महत्वाची असते. सर्च इंजीन्सच्या ह्या relevance चे मूल्यमापन Precision (अचूकता) आणि Recall (?) ह्यांनी केले जाते. ह्या दोन्ही गोष्टी परस्पर पुरक असतात.
Precision (अचूकता): म्हणजे सर्च टर्म नुसार शोध निकालात न दाखवायची वेब पेजेस गाळण्याची (Filter) अचूकता
Recall (?): म्हणजे सर्च टर्म नुसार शोध निकालात दाखवायची वेब पेजेस निवडण्याची अचूकता
आज सर्च इंजीनचे जवळजवळ ८०-८३% मार्केट काबीज करून त्यावर मोनोपॉली असलेल्या गुगलच्या यशाचे 'relevance' हेच मूळ आहे. लॅरी आणि सर्जी ह्या जोडगोळीच्या 'पेजरॅन्क (PageRank)' अल्गोरिदम वर गुगलचा डोलारा उभा आहे. गंमत म्हणजे एकेकाळी त्यांना आणि त्यांच्या ह्याच अल्गोरिदमला कोणीही हिंग लावूनही विचारत नव्हते. शेवटी कंटाळून त्यांनी स्वतःची कंपनी चालू करायचा निर्णय घेतला. :)
या खालच्या चित्रात दाखवल्याप्रमाणे एकंदरीत सर्च इंजीन चालते, बरं का रे भाऊ!
(सर्व चित्रे आंतरजालावरून साभार)
प्रतिक्रिया
22 May 2012 - 12:17 am | विकास
खूप छान आणि माहितीपूर्ण लेख आहे! धन्यवाद. सविस्तर वाचतोय! अजून असेच लेख येउंदेत! :-)
22 May 2012 - 12:37 am | सुनील
छान माहिती.
गुगलने मोनोपॉली निर्माण केली आहे हे खरेच. खरे तर, गुगलणे असे नवे क्रियापदच मराठीत बनू पाहते आहे!
माग काढणे (web crawling) ही क्रिया गुगल अखंडपणे करीत असावे पण तरीही त्याची फ्रिक्वेन्सी काय असावी? दिवसातून एकदा? अनेकदा?
चित्रे दिसत नाहीत.
22 May 2012 - 1:39 am | प्रभाकर पेठकर
गुगलच्या विलक्षण जादूभरल्या जगतातील गल्या-बोळ समजाऊन घेताना गुगलचा 'नकाशा' बर्यापैकी टाळक्यात शिरतो आहे तरी पण हे अगदीच मुलभूत आहे हेही जाणवते आहे. गुगलचा पसारा बघता किती क्लिष्ट असेल हे सर्च इंजीन अशा विचारानेच अचंबित झालो आहे. सोत्री साहेब, धन्यवाद. विचारांना चालना दिलीत.
22 May 2012 - 2:18 am | बॅटमॅन
क्लिष्ट तांत्रिक गोष्टी मराठीत समजावून सांगण्याच्या आपल्या हातोटीला सलाम.
22 May 2012 - 2:35 am | शिल्पा ब
आवडेश.
प्रश्न : सॉफ्टवेअर प्रोग्रामचं नाव स्पायडर आहे का?
रोबोट फाइल बनवुन ठेवली की ऑपॉप स्पायडरला कळतं की यातले पानं वापरायचे नाहीत म्हणुन, की सर्च इंजिन वाल्यांना कळवावं लागतं का कसं?
शेवटचा डायग्राम सोपा दिसत असुन समजला नाही...याचा अर्थ वरचे समजले अशातला भाग नाही पण तरी..
22 May 2012 - 11:19 pm | सोत्रि
नाही, त्या सॉफ्टवेअर प्रकाराला (Category) स्पायडर म्हणतात.
रोबोट फाइल हा स्पायडर आणि वेब साईट यांच्यामधला करार (Mutual Protocol) असतो, ते एक स्टॅन्डर्ड आहे ते दोघांनाही माहिती असते.
- (तांत्रिक) सोकाजी
22 May 2012 - 7:01 am | टवाळ कार्टा
सहीच
22 May 2012 - 7:26 am | चिरोटा
लेख आवडला.चीनमध्ये बायडू हे सर्च इंजिन अतिशय लोकप्रिय आहे असे वाचले आहे.
http://en.wikipedia.org/wiki/Baidu जगभर अजूनही नविन सर्च इंजिन बनवणार्या कंपन्यांत गुंतवणूक होत आहे. ह्याचा अर्थ ह्या क्षेत्रात अजूनही पैसा मिळवायला बराच वाव आहे असे दिसते.
22 May 2012 - 9:15 am | प्रचेतस
अतिशय उत्तम माहिती, तीही अगदी सोप्या भाषेत.
22 May 2012 - 9:33 am | मोदक
+१
22 May 2012 - 9:44 am | श्रावण मोडक
सोत्रि, सोत्रि, तुम्ही मास्तर का नाही हो झालात? ;-)
हा दुसरा लेख झाला. तिसरा कशावर? :-)
22 May 2012 - 11:32 pm | सोत्रि
मास्तर, अग्ग बाब्बो!!! अज्याबात नको हो . एका मास्तरांचा मुलगा असण्याची फळे अजुनही भोगतो आहे.
च्यायला, सरांचा मुलगा ना रे तू, शोभते का तुला हे, काय आदर्श घ्यायचा तुझ्याकडून?
ही असली वाक्ये ऐकून ऐकून सारे शालेय जिवन नासले माझे ;)
- (एका मास्तरांचा मुलगा) सोकाजी
23 May 2012 - 12:18 am | श्रावण मोडक
हे तू कुणाला सांगतो आहेस? :-)
22 May 2012 - 9:45 am | अमृत
आणखी येऊ देत..... ते pagerank मधिल page म्हणजे लॅरी साहेबांचे अडनाव :-) गूगल वर एक डॉक्युमेंट्री बघण्यात आली होती 'The Google Boys'.. आंजावर उपलब्ध असल्यास जरूर बघावी... गूगल करून बघा हा हा हा... :-)
अमृत
22 May 2012 - 10:28 am | चौकटराजा
००१ प्यारा चालू
००२ सः ईक्वल टू तो
००३ अत्रि मीन्स प्राचीन महान ज्ञानी
००४ गिव्हस यू माहिती युजफूल माहिती
००५ गो टू ००१
22 May 2012 - 10:54 am | मी-सौरभ
चायला हे अस्ले प्रश्न आपल्याला कधीच कसे पडत नाहीत :(
22 May 2012 - 11:21 am | नन्दादीप
माहितीपूर्ण लेख.......
22 May 2012 - 11:34 am | किलमाऊस्की
इंग्रजीमधे to google असं क्रियापद आलच आहे. स्पॅनिश्मधे ही Googlear असं क्रियापद आहे.
22 May 2012 - 11:48 am | लॉरी टांगटूंगकर
उत्तम माहिती !!!!
गुगल ला पैसे कसे मिळतात ?
22 May 2012 - 12:15 pm | भडकमकर मास्तर
झैरातीतून
22 May 2012 - 12:05 pm | राजघराणं
माहितीपूर्ण लेख
22 May 2012 - 12:23 pm | भडकमकर मास्तर
मस्त लेख..
एक शंका... गूगल लोकप्रिय होण्यापूर्वी काही सर्च इन्जिन फार भंपक रिझल्ट्स द्यायची ... म्हणजे कार शब्द टाकला तर इन्कारर्नेशन, कार्पेंटर, कार्व्हर वगैरे शब्दातला कार द्यायची... तेव्हा चिडचिड व्हायची... असे का होत होते?
शंका दोन : मिसळपाव च्या सर्च मध्ये काय तां त्रिक अडचणी येतात / येत असाव्यात ज्यामुळे आपले धागे मिसळपावावरून अजिबात सापडत नाहीत पण तेच गूगल ला विचारले की क्षणात उत्तर हजर होते?
अवांतर : ...सगळा लेख वाचला पण नवी आई कशी शोधायची ते दिलंच नाहीये... ;)
22 May 2012 - 12:53 pm | प्रभाकर पेठकर
सगळा लेख वाचला पण नवी आई कशी शोधायची ते दिलंच नाहीये...
हो..! आणि आहे तिच्याशी ह्या विषयावर चर्चा करीत बसलं तर तीही पळून जायची.
22 May 2012 - 2:25 pm | श्रावण मोडक
अगदी, अगदी. मास्तर सांभाळूनच... काये, तुम्ही असा काही शोध घेतला तर तेही गुगल नोंदवून ठेवतं... :-)
22 May 2012 - 2:23 pm | छोटा डॉन
ह्याचे कारण असे आहे की मिपावर जे अनऑफिशियल शोधयंत्र आहे त्याचे नाव 'नंदन' असे आहे.
तुम्ही त्याला हवे ते विचारा, क्षणात उत्तर आणि दुवा हजर होईल. ;)
सोक्याचा लेख मस्तच आहे, त्याची व्हरायटी वाखाणण्याजोगी आहे.
- छोटा डॉन
22 May 2012 - 11:12 pm | सोत्रि
डॉन्राव, आपली पायधूळ मज पामराच्या धाग्याला लागली आणि पावन झाला हा धागा! :)
पण मेगाबायटी प्रतिसादांची परंपरा काही राखली नाहीत आपण, त्यामुळे अंमळ निराशा झाली.
- ( धागा पावन झालेला) सोकाजी
22 May 2012 - 11:07 pm | सोत्रि
एक शंका, उत्तरः गुगलच्या आधिची सर्व सर्च इंजीन्स ही फक्त सर्च टर्म वेब पेजवर किती वेळा आली आहे त्याच्या संख्येनुसार त्या पेवेट 'वेट' करून शोध निकालात दाखवायची. त्यावेळी 'रिलेव्हन्स' ला इतके सिरीयसली घेतले नव्हते कारण गुगल सारखा तगडा प्रतिस्पर्धी त्यांच्याकडे नव्हता. आणि एकंदरीतच 'सर्च' ह्याकडे कोणीही एक 'धंदा' किंवा खुप मोठे मार्केट म्हणून पाहिलेच नव्हते. सगळा हौशी मामला होता. इंतरनेट हे फॅड आहे असे खुद्द बिल गेट्स ला वाटायचे त्या काळी. लॅरी आणि सर्जी जेव्हा त्यांचे पेजरॅन्क अल्गोरिदम घेऊन फिरत होते तेव्हा त्यांना सिरीयसली न घेण्याचे हेच कारण होते. खुद्द याहुमधला त्यांचा मित्र त्यांना हे 'Over engineering' असे म्होता.त्यांना स्वतःची कंपनी चालू करायचा सल्ला दिला होता, जो उपरोधिक असावा असे मला वाटते. दुसरे कारण म्हणजे त्या सर्च इंजीनकडे असणारे त्यावेळचे 'Text Analyzers' हेही अत्याधुनिक नव्हते. गुगलने त्याची मार्केटवरील पकड मजबूत करण्यासाठी ह्या Analyzers मध्येही क्रांती घडवून आणली.
शंका दोन उत्तरः प्रत्येक CMS, Conent Management System चे स्वतःचे सर्च इंजीन असते. मिपा कोणते CMS वापरते त्याची कल्पना नाही, पण Open Source असेल तर बहुदा Lucene ही सर्च लायब्ररी असावी, ती पण Open Source आहे. हा माझा फक्त अंदाज आहे जो चुकीचाही असू शकेल. तर त्यामुळे मराठी भषिक Analyzers नसावेत (हे फक्त व्यावसायिक सर्च इंजीन्स मध्ये असतात) त्यामुळे जी Index (पर्यायाने Taxonomy) बनली आहे ती एकदम टुकार आहे आणि त्यामुळे शोध निकालांचा Precision & Recall गंडलेला असतो.
- (शोधक) सोकाजी
22 May 2012 - 1:06 pm | मोहनराव
अतिशय उत्तम माहीती. हल्ली गुगलशिवाय पान हलत नाही हे अगदी खरं!!
गुगलमधे काही चिन्हे वापरुन आपल्याला आवश्यक ती माहीती नेमकी मिळवता येते, ती पण माहीती दिलीत तर उत्तम होईल.
22 May 2012 - 1:06 pm | पैसा
सोप्या भाषेत उत्तम लेख. काहीही शोधायचं तर घरातलं पुस्तक काढण्यापेक्षा पटकन गुगल पेज ओपन केलं जातं, पण या गुगलण्यामागे एवढी मोठी प्रक्रिया असेल हे कधी लक्षात येत नाही! इतर अनेक सर्च इंजिन्स आहेत खरी, पण गुगल सर्वात लोकप्रिय असावं!
22 May 2012 - 1:36 pm | जातीवंत भटका
माहीतीपूर्ण लेख ! धन्यवाद राजे ..
22 May 2012 - 1:40 pm | स्मिता.
हासुद्धा लेख खूप छान झालाय! क्लिष्ट विषय सोप्या शब्दात समजावून सांगायची छान हातोटी आहे तुमच्याकडे.
इन्फॉर्मेशन/डेटा प्रोसेसिंवर कॉलेजात शिकलं होतं पण त्यावर धूळीचा मोठ्ठा थर बसला होता, हे वाचून थोडसं ब्रश-अप झालं. अश्याच नेहमीच्या वापरातल्या तंत्रज्ञानावर आणखी माहितीपूर्ण लेख येवू द्या.
22 May 2012 - 2:32 pm | श्रावण मोडक
ब्रशनं काही होत नाही. सोत्रि, झाडू घ्या... ;-)
23 May 2012 - 12:10 am | स्मिता.
त्यापेक्षा व्हॅक्युम क्लिनरच घ्या म्हणावं... म्हणजे झाडताना उडालेली धूळ पुन्हा जमणार नाही.
22 May 2012 - 2:18 pm | प्यारे१
+१ टु स्मिता.
>>>क्लिष्ट विषय सोप्या शब्दात समजावून सांगायची छान हातोटी आहे तुमच्याकडे.<<<
खूपच छान माहिती.
अवांतरः याउलट आमच्याकडं सोपे विषय क्लिष्ट शब्दांत सांगणारे वेगवेगळे 'मास्तर, निस्तर नी त्यांचे आयडी' आहेत. ;)
22 May 2012 - 3:14 pm | स्वातीविशु
+१ स्मिता.
22 May 2012 - 3:16 pm | मृत्युन्जय
झक्कास रे सोत्र्या. :)
22 May 2012 - 4:50 pm | सुमीत
ते पण इतक्या सहज सोप्या भाषेत की सर्च इंजिन कसे चालते.
जितक्या सहज पणे वाईन ची सफर घडवलीत तितक्याच सहज पणे आज सर्च इंजिन चे अंतरंग दाखिवलेत.
22 May 2012 - 8:40 pm | नितिन थत्ते
_/\_
मध्यंतरी कुणाला तरी "गुगलकडे कसलीच माहिती नसते. पण त्याला ती माहिती शोधता येते" असे सांगितल्यावर त्याला बसलेला धक्का आठवला.
22 May 2012 - 8:56 pm | अप्पा जोगळेकर
सुंदर लेख. आणखीन तप्शील्वार माहिती आवडली असती. पेपरात १६ मार्कांना हा प्रश्न विचारायचे एवढेच आठवते. बाकी सगळं विसरलो होतो. आभार.
22 May 2012 - 9:10 pm | रेवती
माहिती आवडली पण आंतरजालावरून साभार घेतलेली चित्रं दिसत नाहीत.
एकंदरीतच कोणत्याही सर्चमागे किती प्रकार कार्यरत असतात याचा थोडा अंदाज आला.
कोणतीही माहिती कितीवेळात शोधून दिली त्याचा उल्लेख स्क्रीनवर येतो तेंव्हा आश्चर्य वाटते.
22 May 2012 - 10:32 pm | शिल्पा ब
आधी मला वाटायचं सगळी माहीती गुगल/ याहु गोळा करत असेल...काही लोकं ते एखाद्या सर्व्हरला फीड करत असतील अन आपण सर्च केलं की ते सापडतं असं काहीसं. त्यामुळे रोज येणारी नविन माहीती शोधायला अन साठवायला माणसं ठेवली असतील अशी माझी कल्पना.
23 May 2012 - 9:05 am | शिल्पा ब
स्वारी.
23 May 2012 - 8:19 am | संदीप चित्रे
क्लाउड आणि मग आता सर्च इंजिन...
लगे रहो मुन्नाभाई...
अगदी समोर बसून गप्पा मारल्यासारखे हे क्लिष्ट विषय सोपे करून सांगतोस मित्रा!
कीप इट अप...
(की म्हणू .. कीप डुइंग बॉटम्स अप? ;))
23 May 2012 - 11:08 am | सोत्रि
धन्यवाद,
'बाँटम्स अप'च झँक आहे ;)
-(बाँटमलेस) सोकाजी
23 May 2012 - 11:56 am | चित्रगुप्त
समजा मी एक सुतार आहे, आणि बैलगाडीची चाके बनवतो. मझे नाव 'गंपा सुतार' असे आहे. बैलगाडीची चाके बनवणारे, सुतार आडनाव असणारे जगात शेकडो आहेत. ज्यांना बैलगाडीची चाके बनवून घ्यायची आहेत, परंतु माझ्या विषयी ज्यांना काहीही ठाउक नाही, त्यांनी गूगल वर सर्च केल्यावर माझे नाव, माझ्या कामाचे फोटो इ. त्यांना दिसावे, यासाठी काही करता येते का ? असल्यास काय? ते विनामूल्य आहे का?
23 May 2012 - 12:17 pm | jaypal
सोत्रि तुम्ही खरच मास्तर व्हा. कठिण विषय सोप्पा करुन सांगण्याची कला खुप कमी लोकांकडे असते आणि अस्से मास्तर तर त्या हुनही विराळाच.
23 May 2012 - 12:42 pm | जे.पी.मॉर्गन
बर्याच दिवसांनी मिपावर आलो आणि हा लेख आणि खालचे प्रतिसाद वाचण्यात वेळ कसा गेला समजलंच नाही. लई झ्याक्क जमलाय. सगळा प्रकार यथास्थित डीकोड करून सांगितला आहेस. खरंच क्लिष्ट गोष्ट सोपी करून सांगण्याच्या तुझ्या हातोटीला सलाम. तुझी पृथःकरण आणि सूचीकरणाची कला अफाट आहे मित्रा. मग ते वारुणीबद्दल असो वा सर्च इंजिन्सबद्दल!
बरं... तुझा क्लाऊड वरचा लेख गूगलून बघतो... मिपाच्या इंजिनावर सापडायचा नाही ;)
ह्यानंतर एस ई ओ (सर्च इंजिन ऑप्टिमायझेशन) वर काही लिहू शकशील?
जे.पी.
23 May 2012 - 1:50 pm | सोत्रि
SEO वर लिहायचा विचार होताच, पण आता तुझ्या ह्या प्रतिसादानंतर तो द्रुढ झाला. ह्या विषयावर माझा एक ह्वाईट पेपर पण आहे तसेच एक प्रोव्हीजनल पेटंटही आहे नावावर :)
-(तांत्रिक )सोकाजी
23 May 2012 - 2:55 pm | प्राजक्ता पवार
माहितीपूर्ण लेख :)